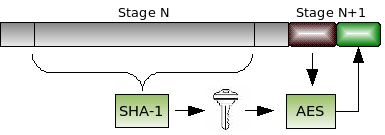
Hash functions are an excellent way to tie together various parts of a protection mechanism. Our first mesh design pattern, hash-and-decrypt, uses a hash function to derive a key that is then used to decrypt the next stage. Since a cryptographic hash (e.g., SHA-1) is sensitive to a change of even a single bit of input, this pattern provides a strong way to insure the next stage (code, data, more checks) is not accessible unless all the input bits are correct.
For example, consider a game with different levels, each encrypted with a different AES key. The key to decrypt level N+1 can be derived by hashing together data which only is present in RAM after the player has beat level N with an unmodified game (e.g., correct items in inventory, state of treasure chests, map of locations visited, etc.) If an attacker tries to cheat on level N by modifying the game state, they won’t know what items they need to have, may load up their character with items that are impossible to have at that point in the game, or one or more map positions won’t have been marked as visited. In this case, the hash and thus the next level key will be incorrect. Any difference in the hashed data produces an incorrect key and the level cannot be decrypted without the exact key.
In software protection, the focus is on verifying that security checks are intact and running properly. Hash-and-decrypt would cover code and data locations that might be modified by an attacker who is debugging or patching the application in order to reverse engineer it. This includes locations that might be changed by setting breakpoints (i.e., int 3 or Detours-style function hooking, debug registers DR0-3, IDTR a la Red Pill) or self-check functions that may be disabled or paused while analyzing the executable. The encrypted stage N+1 can be parts of the application as well as other self-check functions.
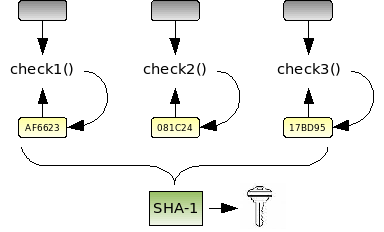
To tie together multiple self-check functions, hash-and-decrypt can also be layered. For example, each self-check function, which monitors one or more different hook points, can iteratively hash a unique seed each time it runs along with the data it observes. The unlock function hashes each self-check’s hash, decrypts, and then executes the protected code. If an attacker pauses one or more of the self-check threads, the hash will be incorrect when the unlock function runs.
To slow down the attacker, invariants that are not security-critical can be included in the hash (“chaff”). For example, the game could hash parts of RAM that are known to be constants or map data. This keeps the hashed addresses from pointing out what’s important. This falls under the category of obfuscation techniques, but is a good example of how each software protection method mutually enforces each other.
Finally, this technique can be implemented in hardware to prevent glitching attacks. In a glitching attack, a pulse is used to disrupt a processor’s execution (usually via the clock line), causing some operation to be performed incorrectly. Attackers can use this to target internal logic and trigger malicious code execution in tamper-resistant devices. To counter this, the internal state (i.e. pipeline registers, address lines, caches, IR) of the processor can be hashed by custom hardware each clock cycle. At the end of each instruction, the final hash is used to unlock the next operation. If a glitch caused the value of any flip-flop in the CPU to be incorrect during any of the intermediate clock cycles, the next operation will not decrypt properly.



